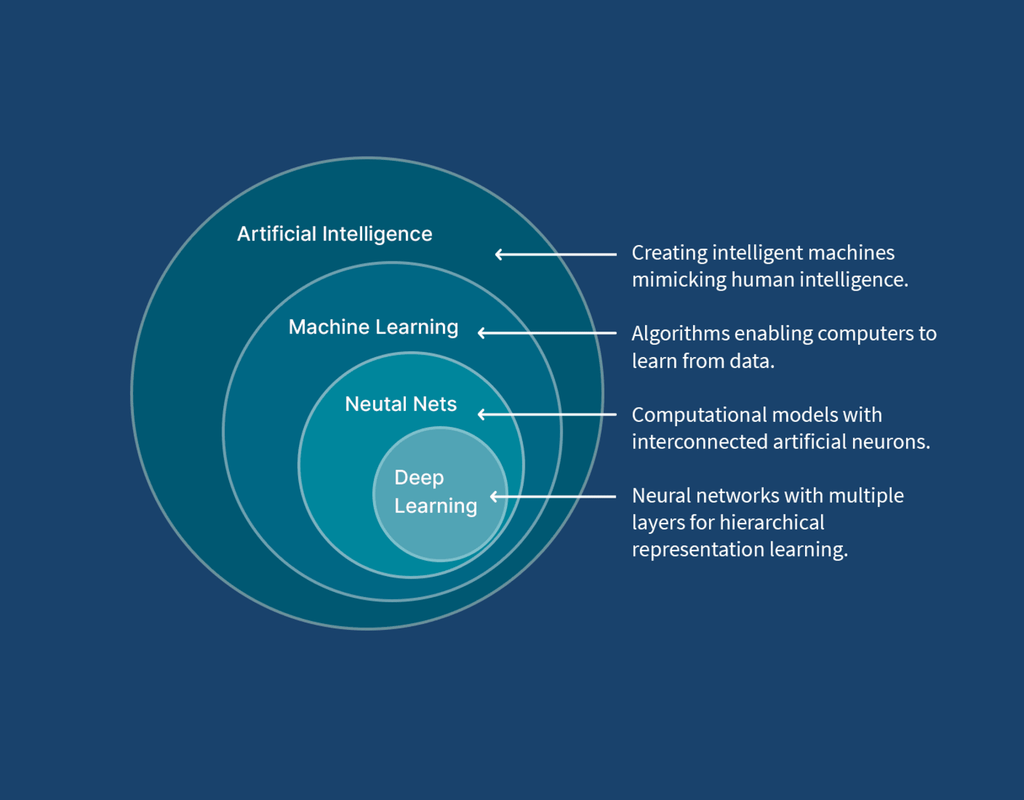
Machine learning (ML) is a subset of artificial intelligence (AI) that enables systems to learn from data and improve over time without being explicitly programmed. One of the fundamental distinctions in machine learning is between supervised and unsupervised learning. These two approaches differ in how they process data, the types of problems they solve, and their real-world applications.
In this blog, we will explore the key differences between supervised and unsupervised learning, their advantages and disadvantages, use cases, and how to choose the right approach for your machine-learning project.
Related: What is reinforcement learning in AI, and how is it different from supervised and unsupervised learning?
What Is Supervised Learning?
Supervised learning is a machine learning technique where the model is trained on a labeled dataset. This means that the input data is paired with the correct output (label), and the algorithm learns to map inputs to the desired outputs.
Key Characteristics of Supervised Learning:
Requires labeled training data.
The model makes predictions based on past examples.
Used for classification and regression problems.
Performance is evaluated using accuracy, precision, recall, and other metrics.
Types of Supervised Learning
A. Classification
Classification involves predicting a discrete label (category). Examples include:
Email spam detection (spam or not spam)
Image recognition (cat, dog, bird)
Medical diagnosis (disease or no disease)
Popular algorithms:
Logistic Regression
Decision Trees
Support Vector Machines (SVM)
Random Forest
Neural Networks
B. Regression
Regression predicts a continuous numerical value. Examples include:
House price prediction
Stock market forecasting
Temperature prediction
Popular algorithms:
Linear Regression
Polynomial Regression
Ridge & Lasso Regression
Decision Trees (for regression)
You May Also Like: What is the difference between machine learning and deep learning?
Advantages of Supervised Learning
Clear objectives (since labeled data is provided).
Easy to evaluate performance using metrics.
Works well for problems with historical labeled data.
Disadvantages of Supervised Learning
Requires large labeled datasets (which can be expensive).
May not generalize well if training data is biased.
Time-consuming to annotate data manually.
What Is Unsupervised Learning?
Unsupervised learning involves training models on unlabeled data. The system tries to find hidden patterns or groupings without explicit guidance.
Key Characteristics of Unsupervised Learning:
Works with unlabeled data.
Discovers hidden structures in data.
Used for clustering, dimensionality reduction, and association tasks.
Harder to evaluate since there are no predefined labels.
Types of Unsupervised Learning
A. Clustering
Clustering groups similar data points together. Examples include:
Customer segmentation (grouping users by behavior)
Anomaly detection (identifying fraud in transactions)
Document clustering (organizing news articles by topic)
Popular algorithms:
K-Means Clustering
Hierarchical Clustering
DBSCAN
Gaussian Mixture Models (GMM)
B. Dimensionality Reduction
Reduces the number of features while retaining important information. Examples:
Image compression
Feature extraction for supervised learning
Popular algorithms:
Principal Component Analysis (PCA)
t-SNE (t-Distributed Stochastic Neighbor Embedding)
Autoencoders (Neural Networks)
C. Association Rule Learning
Finds relationships between variables in large datasets. Examples:
Market basket analysis (recommending products based on purchases)
Netflix recommendations (suggesting movies based on viewing history)
Popular algorithms:
Apriori Algorithm
FP-Growth
Advantages of Unsupervised Learning.

Disadvantages of Unsupervised Learning
No clear evaluation metrics (since there’s no ground truth).
Results can be harder to interpret.
May produce irrelevant clusters if data is noisy.
Key Differences Between Supervised and Unsupervised Learning
Which One Should You Use?
When to Use Supervised Learning?
✔ You have labeled training data.
✔ You need to predict a specific outcome (classification/regression).
✔ Examples: Fraud detection, medical diagnosis, sentiment analysis.
When to Use Unsupervised Learning?
✔ You have unlabeled data and want to explore hidden trends.
✔ You need to group similar data points (customer segmentation).
✔ Examples: Recommendation systems, anomaly detection, data preprocessing.
Semi-Supervised Learning (Hybrid Approach)
In real-world scenarios, data is often partially labeled. Semi-supervised learning combines both approaches, using a small labeled dataset alongside a larger unlabeled dataset. This is useful when labeling data is expensive.
Real-World Applications
Supervised Learning Examples
Healthcare: Predicting diseases from medical scans.
Finance: Credit scoring (approving/rejecting loans).
E-commerce: Personalized product recommendations.
Unsupervised Learning Examples
Marketing: Segmenting customers for targeted ads.
Cybersecurity: Detecting unusual network traffic.
Retail: Market basket analysis (Amazon’s "Frequently bought together").
Conclusion
Supervised and unsupervised learning serve different purposes in machine learning:
Supervised Learning is best when you have labeled data and need predictions (classification/regression).
Unsupervised Learning excels at discovering hidden structures in unlabeled data (clustering, dimensionality reduction).
Choosing the right approach depends on your data and problem type. In practice, many advanced AI systems (like recommendation engines) use a combination of both techniques for optimal results.
As AI continues to evolve, understanding these fundamental concepts will help you build better machine-learning models and leverage data effectively.
 Nikhil Rajawat
Nikhil Rajawat
Machine learning (ML) is a subset of artificial intelligence (AI) that enables systems to learn from data and improve over time without being explicitly programmed. One of the fundamental distinctions in machine learning is between supervised and unsupervised learning. These two approaches differ in how they process data, the types of problems they solve, and their real-world applications.
In this blog, we will explore the key differences between supervised and unsupervised learning, their advantages and disadvantages, use cases, and how to choose the right approach for your machine-learning project.
Related: What is reinforcement learning in AI, and how is it different from supervised and unsupervised learning?
What Is Supervised Learning?
Supervised learning is a machine learning technique where the model is trained on a labeled dataset. This means that the input data is paired with the correct output (label), and the algorithm learns to map inputs to the desired outputs.
Key Characteristics of Supervised Learning:
Requires labeled training data.
The model makes predictions based on past examples.
Used for classification and regression problems.
Performance is evaluated using accuracy, precision, recall, and other metrics.
Types of Supervised Learning
A. Classification
Classification involves predicting a discrete label (category). Examples include:
Email spam detection (spam or not spam)
Image recognition (cat, dog, bird)
Medical diagnosis (disease or no disease)
Popular algorithms:
Logistic Regression
Decision Trees
Support Vector Machines (SVM)
Random Forest
Neural Networks
B. Regression
Regression predicts a continuous numerical value. Examples include:
House price prediction
Stock market forecasting
Temperature prediction
Popular algorithms:
Linear Regression
Polynomial Regression
Ridge & Lasso Regression
Decision Trees (for regression)
You May Also Like: What is the difference between machine learning and deep learning?
Advantages of Supervised Learning
Clear objectives (since labeled data is provided).
Easy to evaluate performance using metrics.
Works well for problems with historical labeled data.
Disadvantages of Supervised Learning
Requires large labeled datasets (which can be expensive).
May not generalize well if training data is biased.
Time-consuming to annotate data manually.
What Is Unsupervised Learning?
Unsupervised learning involves training models on unlabeled data. The system tries to find hidden patterns or groupings without explicit guidance.
Key Characteristics of Unsupervised Learning:
Works with unlabeled data.
Discovers hidden structures in data.
Used for clustering, dimensionality reduction, and association tasks.
Harder to evaluate since there are no predefined labels.
Types of Unsupervised Learning
A. Clustering
Clustering groups similar data points together. Examples include:
Customer segmentation (grouping users by behavior)
Anomaly detection (identifying fraud in transactions)
Document clustering (organizing news articles by topic)
Popular algorithms:
K-Means Clustering
Hierarchical Clustering
DBSCAN
Gaussian Mixture Models (GMM)
B. Dimensionality Reduction
Reduces the number of features while retaining important information. Examples:
Image compression
Feature extraction for supervised learning
Popular algorithms:
Principal Component Analysis (PCA)
t-SNE (t-Distributed Stochastic Neighbor Embedding)
Autoencoders (Neural Networks)
C. Association Rule Learning
Finds relationships between variables in large datasets. Examples:
Market basket analysis (recommending products based on purchases)
Netflix recommendations (suggesting movies based on viewing history)
Popular algorithms:
Apriori Algorithm
FP-Growth
Advantages of Unsupervised Learning.
Disadvantages of Unsupervised Learning
No clear evaluation metrics (since there’s no ground truth).
Results can be harder to interpret.
May produce irrelevant clusters if data is noisy.
Key Differences Between Supervised and Unsupervised Learning
Which One Should You Use?
When to Use Supervised Learning?
✔ You have labeled training data.
✔ You need to predict a specific outcome (classification/regression).
✔ Examples: Fraud detection, medical diagnosis, sentiment analysis.
When to Use Unsupervised Learning?
✔ You have unlabeled data and want to explore hidden trends.
✔ You need to group similar data points (customer segmentation).
✔ Examples: Recommendation systems, anomaly detection, data preprocessing.
Semi-Supervised Learning (Hybrid Approach)
In real-world scenarios, data is often partially labeled. Semi-supervised learning combines both approaches, using a small labeled dataset alongside a larger unlabeled dataset. This is useful when labeling data is expensive.
Real-World Applications
Supervised Learning Examples
Healthcare: Predicting diseases from medical scans.
Finance: Credit scoring (approving/rejecting loans).
E-commerce: Personalized product recommendations.
Unsupervised Learning Examples
Marketing: Segmenting customers for targeted ads.
Cybersecurity: Detecting unusual network traffic.
Retail: Market basket analysis (Amazon’s "Frequently bought together").
Conclusion
Supervised and unsupervised learning serve different purposes in machine learning:
Supervised Learning is best when you have labeled data and need predictions (classification/regression).
Unsupervised Learning excels at discovering hidden structures in unlabeled data (clustering, dimensionality reduction).
Choosing the right approach depends on your data and problem type. In practice, many advanced AI systems (like recommendation engines) use a combination of both techniques for optimal results.
As AI continues to evolve, understanding these fundamental concepts will help you build better machine-learning models and leverage data effectively.